MySQL 中默认的存储引擎 InnoDB 的索引是使用 B+ 树实现的。B+ 树是一种多路搜索树,它的叶子节点存储了所有的数据行信息,叶子节点之间使用指针连接,方便范围查询和排序等操作,非叶子节点存储的是索引字段的值,这样就可以通过非叶子节点的索引值快速定位到叶子节点的数据了,索引的实现如下图所示: 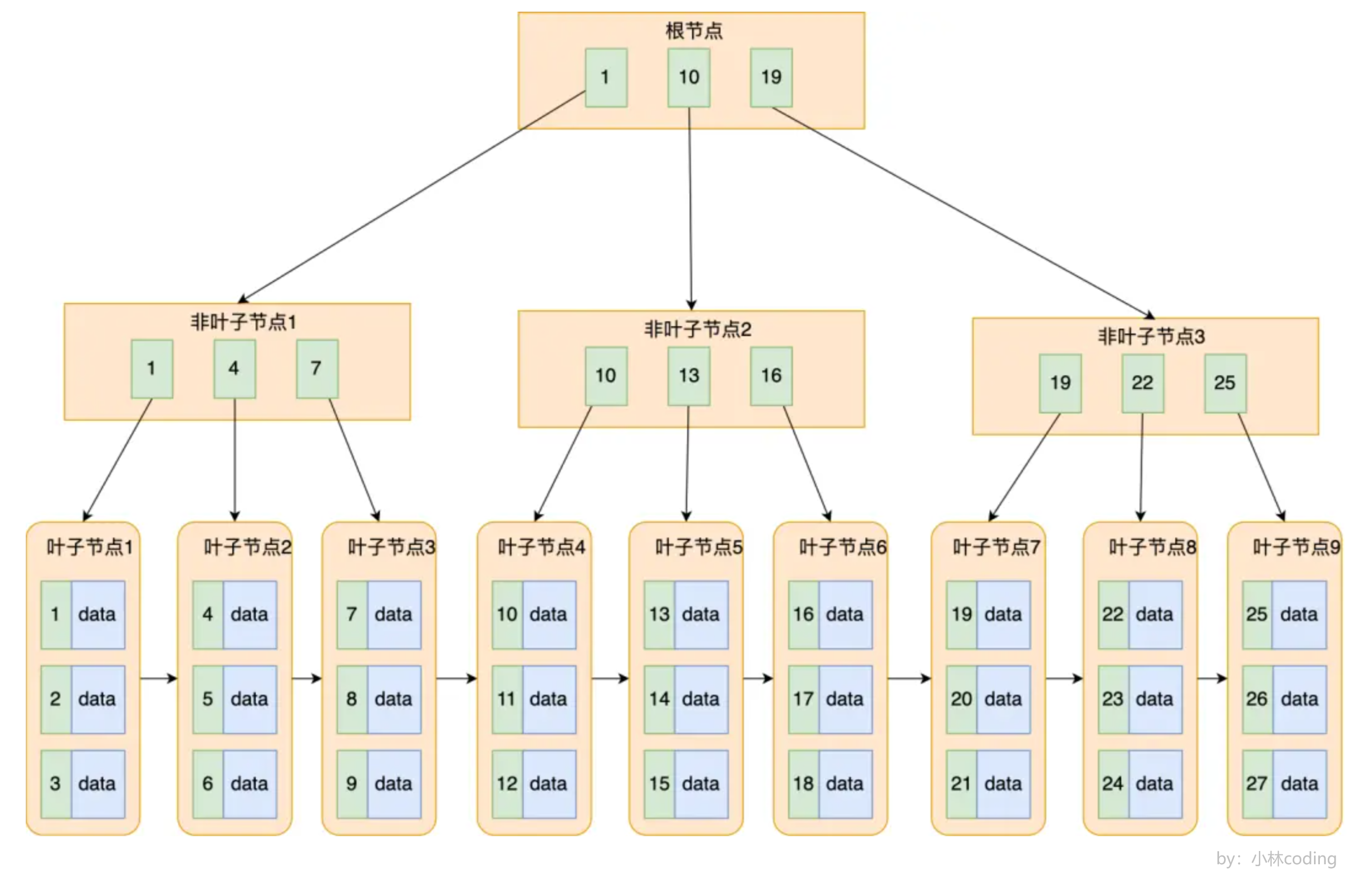
B+ 树优点分析
1.查询效率
B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比即存索引又存记录的 B 树,B+ 树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O 次数会更少。
2.插入和删除效率
B+ 树有大量的冗余节点,这样使得删除一个节点的时候,可以直接从叶子节点中删除,甚至可以不动非叶子节点,这样删除非常快, 比如下面这个动图是删除 B+ 树 0004 节点的过程,因为非叶子节点有 0004 的冗余节点,所以在删除的时候,树形结构变化很小:
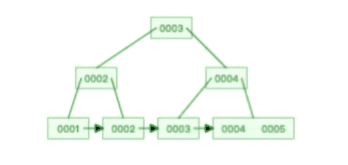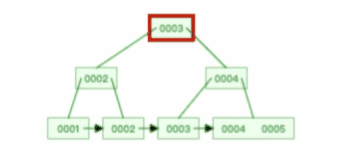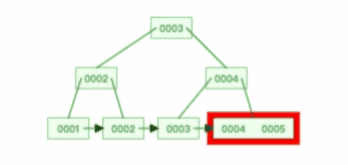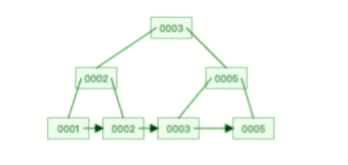
B 树则不同,B 树没有冗余节点,删除节点的时候非常复杂,比如删除根节点中的数据,可能涉及复杂的树的变形,比如下面这个动图是删除 B 树根节点的过程:

B+ 树的插入也是一样,有冗余节点,插入可能存在节点的分裂(如果节点饱和),但是最多只涉及树的一条路径。而且 B+ 树会自动平衡,不需要像更多复杂的算法,类似红黑树的旋转操作等。因此,B+ 树的插入和删除效率更高。
3.范围查询
因为 B+ 树所有叶子节点间还有一个链表进行连接,这种设计对范围查找非常有帮助,比如说我们想知道 12 月 1 日和 12 月 12 日之间的订单,这个时候可以先查找到 12 月 1 日所在的叶子节点,然后利用链表向右遍历,直到找到 12 月12 日的节点,这样就不需要从根节点查询了,进一步节省查询需要的时间。
而 B 树没有将所有叶子节点用链表串联起来的结构,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
因此,存在大量范围检索的场景,适合使用 B+树。
参考 & 鸣谢
小林coding公众号
特殊说明
以上内容来自我的《Java 面试突击训练营》,这门课程是有着十几年工作经验(前 360 开发工程师),10 年面试官经验的我,花费 4 年时间打磨完成的一门视频面试课。学完训练营的课程之后,基本可以应对目前市面上绝大部分公司的面试了,并且课程配备了 9 大就业服务,帮助上千人找到 Java 工作,其中上百人拿到大厂 Offer,学员最高薪资 70W 年薪,面试课目录和 9 大服务如下:

加我微信咨询:vipStone【备注:训练营】
