聚簇索引和非聚簇索引都是用于加速数据库查询的索引类型,它们的主要区别在于数据的存储和查询上。
概念说明
聚簇索引(Clustered Index)也被称为聚集索引,在 InnoDB 存储引擎中,每个表只能有一个聚集索引,其余的索引都是非聚集索引(也称为二级索引)。
聚集索引是按照数据在磁盘上的物理顺序来组织数据的,其叶子节点保存着完整的数据行信息。InnoDB 中,如果表定义了主键,则主键索引是聚集索引;如果表没有定义主键,则第一个唯一非空索引是聚集索引;如果都没有,则 InnoDB 会隐式创建一个隐藏的聚集索引。
例如,我们创建一张 student 表,它的构建 SQL 如下:
drop table if exists student;
create table student(
id int primary key,
name varchar(16),
class_id int not null,
index (class_id)
)engine=InnoDB;
-- 添加测试数据
insert into student(id,name,class_id) values(100,'张三',1),
(200,'李四',2),(300,'王五',3);
以上 student 表中有一个聚簇索引(也就是主键索引)id,和一个非聚簇索引 class_id。 聚簇索引 id 对应存储结构如下图所示: 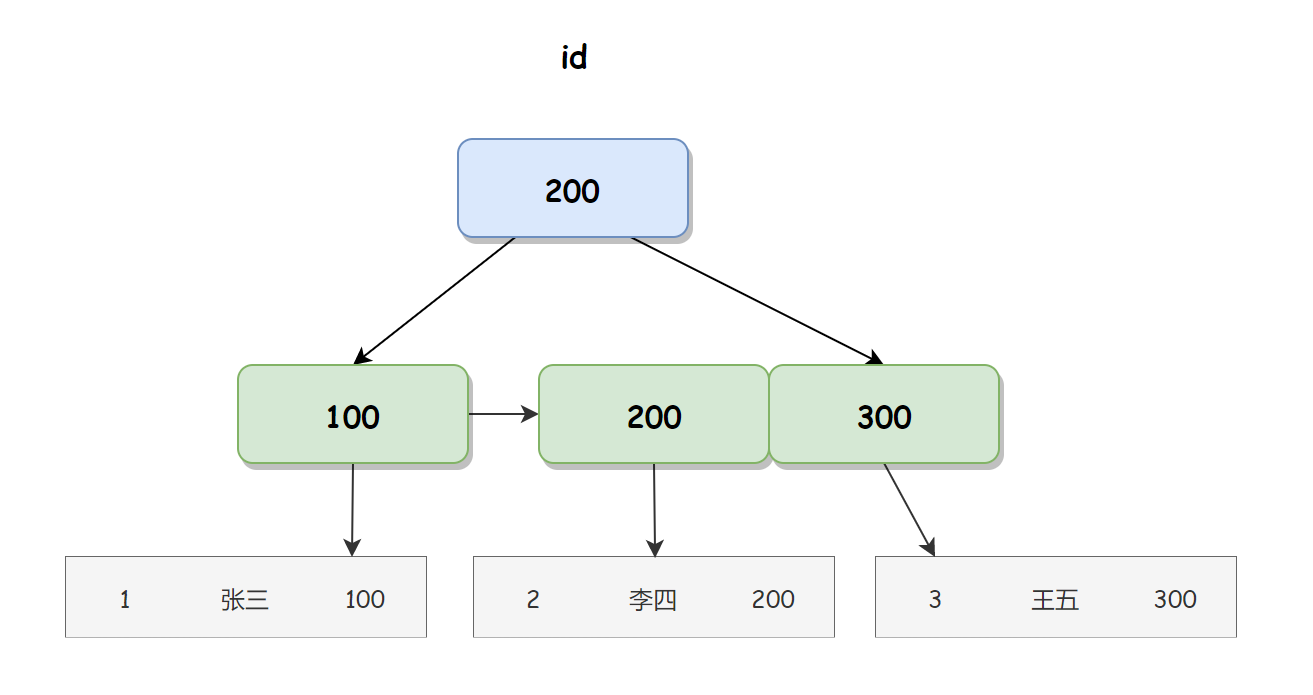 非聚集索引也叫二级索引,其叶子节点保存着索引字段和指向对应数据行的指针(相当于主键 ID),通过这个指针可以找到对应的数据行。在查询中,如果使用的是非聚集索引,则需要先根据索引查找到对应的行指针,再通过行指针查找数据行,这个过程叫做回表查询,因此他的查询速度相对于聚集索引要慢一些。
非聚集索引也叫二级索引,其叶子节点保存着索引字段和指向对应数据行的指针(相当于主键 ID),通过这个指针可以找到对应的数据行。在查询中,如果使用的是非聚集索引,则需要先根据索引查找到对应的行指针,再通过行指针查找数据行,这个过程叫做回表查询,因此他的查询速度相对于聚集索引要慢一些。
以上面 student 表为例,在 student 中非聚簇索引 class_id 对应存储结构如下图所示:  从上图我们可以看出,在非聚簇索引的叶子节点上存储的并不是真正的行数据,而是主键 ID,所以当我们使用非聚簇索引进行查询时,首先会得到一个主键 ID,然后再使用主键 ID 去聚簇索引上找到真正的行数据,所以查询速度要慢一些。
从上图我们可以看出,在非聚簇索引的叶子节点上存储的并不是真正的行数据,而是主键 ID,所以当我们使用非聚簇索引进行查询时,首先会得到一个主键 ID,然后再使用主键 ID 去聚簇索引上找到真正的行数据,所以查询速度要慢一些。
聚簇索引 VS 非聚簇索引
聚簇索引和非聚簇索引的区别主要有以下几点:
- 存储数据不同:聚簇索引将数据行存储在与索引相同的 B+ 树结构中,而非聚簇索引是将索引和主键 ID 存储在 B+ 树结构中;
- 数量限制不同:一张表只能有一个聚簇索引,但可以有多个非聚簇索引;
- 索引更新不同:由于聚簇索引中的数据行与索引行是一一对应的,因此对于聚簇索引的任何更新都需要重新排列数据行的物理顺序。这可能会导致性能问题,特别是在高并发环境中,而非聚簇索引的更新不需要重新排列数据行的物理顺序,因为索引和数据行是分开存储的;
- 索引大小不同:由于聚簇索引中的数据行与索引行是一一对应的,因此聚簇索引的大小通常比非聚簇索引大,而非聚簇索引通常比较小,因为它们只存储索引不存储数据行;
- 范围查询不同:聚簇索引中的数据行与索引行是一一对应的,因此聚簇索引通常比非聚簇索引更适合范围查询,而非聚簇索引需要进行两次查找:首先查找索引,然后查找数据行,这可能会导致性能问题,特别是在大型表上进行范围查询时。
特殊说明
以上内容来自我的《Java 面试突击训练营》,这门课程是有着十几年工作经验(前 360 开发工程师),10 年面试官经验的我,花费 4 年时间打磨完成的一门视频面试课。学完训练营的课程之后,基本可以应对目前市面上绝大部分公司的面试了,并且课程配备了 9 大就业服务,帮助上千人找到 Java 工作,其中上百人拿到大厂 Offer,学员最高薪资 70W 年薪,面试课目录和 9 大服务如下:

加我微信咨询:vipStone【备注:训练营】
