面试题目来源于牛客,如下图所示:
答案解析
1.解释脏读/不可重复读/幻读
- 脏读:指一个事务读取到了另一个事务为提交保存的数据,之后此事务进行了回滚操作,从而导致第一个事务读取了一个不存在的脏数据。
- 不可重复读:在同一个事务中,同一个查询在不同的时间得到了不同的结果。例如事务在 T1 读取到了某一行数据,在 T2 时间重新读取这一行时候,这一行的数据已经发生修改,所以再次读取时得到了一个和 T1 查询时不同的结果。
- 幻读:同一个查询在不同时间得到了不同的结果,这就是事务中的幻读问题。例如,一个 SELECT 被执行了两次,但是第二次返回了第一次没有返回的一行,那么这一行就是一个“幻像”行。
不可重复读和幻读的区别
- 不可重复读的重点是修改:在同一事务中,同样的条件,第一次读的数据和第二次读的数据不一样。(因为中间有其他事务提交了修改);
- 幻读的重点在于新增或者删除:在同一事务中,同样的条件,,第一次和第二次读出来的记录数不一样。(因为中间有其他事务提交了插入/删除)。
2.索引失效的场景有哪些?
常见的索引失效场景有以下这些:
- 未遵循最左匹配原则
- 使用列运算
- 使用函数方法
- 类型转换
- 使用 is not null
- 错误的模糊匹配,使用右 % 开始查询。
具体内容请参考:https://www.javacn.site/interview/mysql/indexinvalid.html
3.Explain执行计划用过吗?
Explain 是用来分析 SQL 的执行情况的,explain 使用如下,只需要在查询的 SQL 前面添加上 explain 关键字即可,如下图所示:

而以上查询结果的列中,我们最主要观察 key 这一列,key 这一列表示实际使用的索引,如果为 NULL 则表示未使用索引,反之则使用了索引。
以上所有结果列说明如下:
- id — 选择标识符,id 越大优先级越高,越先被执行;
- select_type — 表示查询的类型;
- table — 输出结果集的表;
- partitions — 匹配的分区;
- type — 表示表的查询类型;
- possible_keys — 表示查询时,可能使用的索引;
- key — 表示实际使用的索引;
- key_len — 索引字段的长度;
- ref— 列与索引的比较;
- rows — 大概估算的行数;
- filtered — 按表条件过滤的行百分比;
- Extra — 执行情况的描述和说明。
4.Type字段有什么信息?
Explain 执行计划中最重要的就是 type 字段,type 包含的信息如下:
- all — 扫描全表数据;
- index — 遍历索引;
- range — 索引范围查找;
- index_subquery — 在子查询中使用 ref;
- unique_subquery — 在子查询中使用 eq_ref;
- ref_or_null — 对 null 进行索引的优化的 ref;
- fulltext — 使用全文索引;
- ref — 使用非唯一索引查找数据;
- eq_ref — 在 join 查询中使用主键或唯一索引关联;
- const — 将一个主键放置到 where 后面作为条件查询, MySQL 优化器就能把这次查询优化转化为一个常量,如何转化以及何时转化,这个取决于优化器,这个比 eq_ref 效率高一点。
5.binlog和redolog区别?
binlog(二进制日志)和 redolog(重做日志)都是 MySQL 中的重要日志,但二者存在以下不同。
- binlog(二进制日志):
- binlog 是 MySQL 的服务器层日志,用于记录对数据库执行的所有修改操作,包括插入、更新和删除等。它以二进制格式记录,可以被用于数据复制、恢复和故障恢复等操作。
- binlog 记录了逻辑上的操作,即执行的 SQL 语句或语句的逻辑表示。
- binlog 是在事务提交后才会生成,因此它是持久化的。
- binlog 可以被配置为不同的格式,包括基于语句的复制(statement-based replication)、基于行的复制(row-based replication)和混合复制(mixed replication)。
- redolog(重做日志):
- redolog 是 MySQL 的存储引擎层日志,用于确保数据库的事务持久性和崩溃恢复能力。
- redolog 记录了物理层面的修改操作,即对数据页的物理修改。它主要用于保证事务的持久性,确保在发生崩溃时,已经提交的事务对数据库的修改能够被恢复。
- redolog 是循环写入的,它的数据写入到磁盘上的文件中。在发生崩溃时,通过 redolog 的重做操作,可以将数据库恢复到崩溃前的一致状态。
- redolog 是在事务执行期间不断写入的,以确保在系统崩溃时可以重做所有已提交的事务。
小结:binlog 用于记录逻辑层面的操作,可以用于数据复制和恢复,而 redolog 用于记录物理层面的操作,确保事务的持久性和崩溃恢复。它们在功能和使用上有一些不同,但都是 MySQL 中重要的日志机制。
6.Redis基本数据类型
Redis 常用的数据类型有 5 种:String 字符串类型、List 列表类型、Hash 哈希表类型、Set 集合类型、Sorted Set 有序集合类型,如下图所示: 这 5 种常用类型的用途如下:
- String:字符串类型,常见使用场景是:存储 Session 信息、存储缓存信息(如详情页的缓存)、存储整数信息,可使用 incr 实现整数+1,和使用 decr 实现整数 -1;
- List:列表类型,常见使用场景是:实现简单的消息队列、存储某项列表数据;
- Hash:哈希表类型,常见使用场景是:存储 Session 信息、存储商品的购物车,购物车非常适合用哈希字典表示,使用人员唯一编号作为字典的 key,value 值可以存储商品的 id 和数量等信息、存储详情页信息;
- Set:集合类型,是一个无序并唯一的键值集合,它的常见使用场景是:关注功能,比如关注我的人和我关注的人,使用集合存储,可以保证人员不会重复;
- Sorted Set:有序集合类型,相比于 Set 集合类型多了一个排序属性 score(分值),它的常见使用场景是:可以用来存储排名信息、关注列表功能,这样就可以根据关注实现排序展示了。
更多内容请参考:https://www.javacn.site/interview/redis/types.html
7.有序集合底层实现数据结构?
有序集合是由 ziplist (压缩列表) 或 skiplist (跳跃表) 组成的。
- 压缩列表 ziplist 本质上就是一个字节数组,是 Redis 为了节约内存而设计的一种线性数据结构,可以包含多个元素,每个元素可以是一个字节数组或一个整数。
- 跳跃表 skiplist 是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。跳跃表支持平均 O(logN)、最坏 O(N) 复杂度的节点查找,还可以通过顺序性操作来批量处理节点。
当数据比较少时,有序集合是压缩列表 ziplist 存储的(反之则为跳跃表 skiplist 存储),使用压缩列表存储必满足以下两个条件:
- 有序集合保存的元素个数要小于 128 个;
- 有序集合保存的所有元素成员的长度都必须小于 64 字节。
如果不能满足以上两个条件中的任意一个,有序集合将会使用跳跃表 skiplist 结构进行存储。
8.跳表插入数据的过程?
在开始讲跳跃表的添加流程之前,必须先搞懂一个概念:节点的随机层数。 所谓的随机层数指的是每次添加节点之前,会先生成当前节点的随机层数,根据生成的随机层数来决定将当前节点存在几层链表中。
为什么要这样设计呢?
这样设计的目的是为了保证 Redis 的执行效率。
为什么要生成随机层数,而不是制定一个固定的规则,比如上层节点是下层跨越两个节点的链表组成,如下图所示:

如果制定了规则,那么就需要在添加或删除时,为了满足其规则,做额外的处理,比如添加了一个新节点,如下图所示:

这样就不满足制定的上层节点跨越下层两个节点的规则了,就需要额外的调整上层中的所有节点,这样程序的效率就降低了,所以使用随机层数,不强制制定规则,这样就不需要进行额外的操作,从而也就不会占用服务执行的时间了。
添加流程
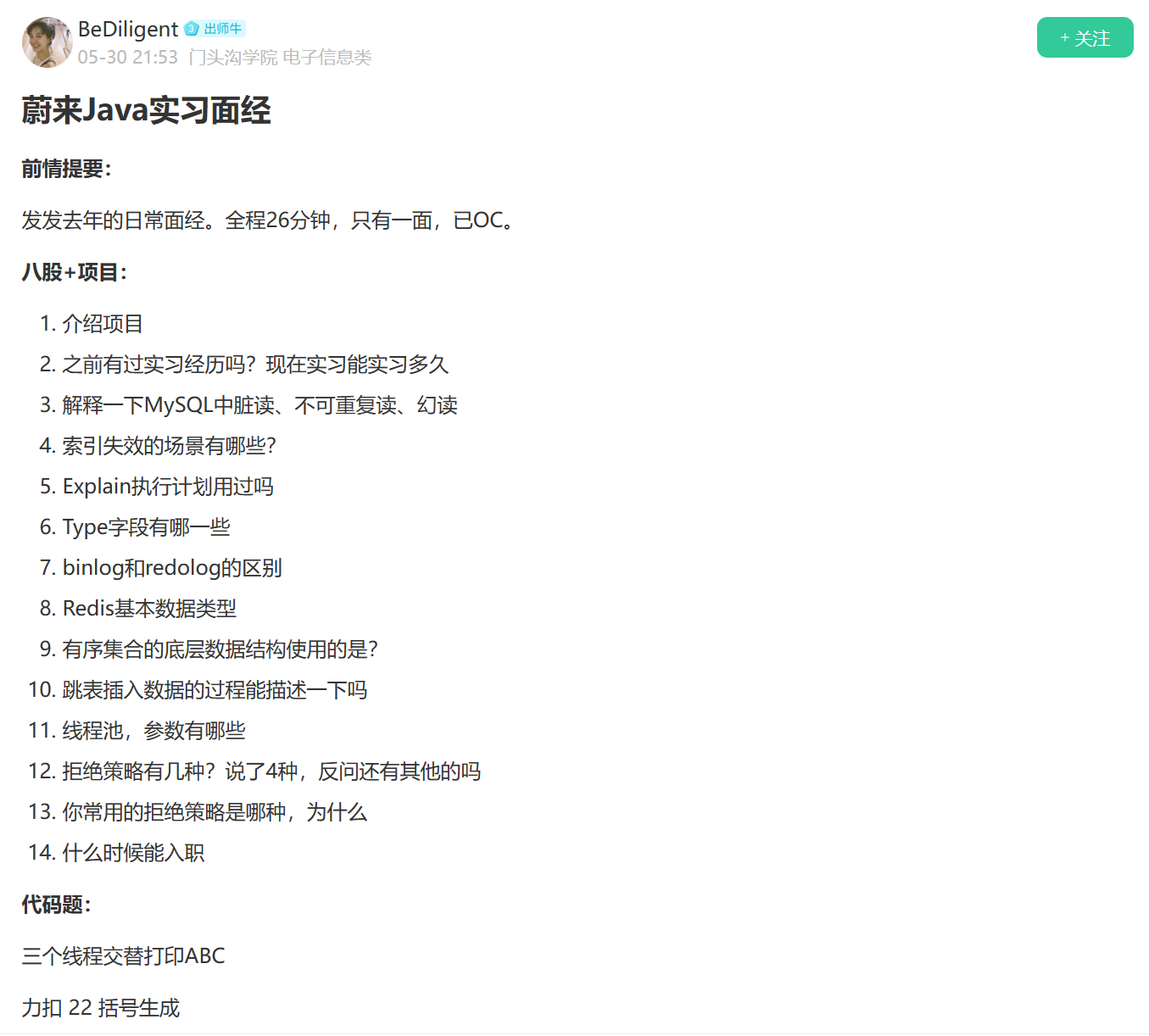
Redis 中跳跃表的添加流程如下图所示:
- 第一个元素添加到最底层的有序链表中(最底层存储了所有元素数据)。
- 第二个元素生成的随机层数是 2,所以再增加 1 层,并将此元素存储在第 1 层和最低层。
- 第三个元素生成的随机层数是 4,所以再增加 2 层,整个跳跃表变成了 4 层,将此元素保存到所有层中。
- 第四个元素生成的随机层数是 1,所以把它按顺序保存到最后一层中即可。
其他新增节点以此类推。 更多内容请参考:https://www.javacn.site/company/redis_skiplist.html
9.线程池有哪些参数?
线程池(ThreadPoolExecutor)有 7 个参数,这 7 个参数的含义如下:
- 第 1 个参数:corePoolSize 表示线程池的常驻核心线程数。如果设置为 0,则表示在没有任何任务时,销毁线程池;如果大于 0,即使没有任务时也会保证线程池的线程数量等于此值。但需要注意,此值如果设置的比较小,则会频繁的创建和销毁线程(创建和销毁的原因会在本课时的下半部分讲到);如果设置的比较大,则会浪费系统资源,所以开发者需要根据自己的实际业务来调整此值;
- 第 2 个参数:maximumPoolSize 表示线程池在任务最多时,最大可以创建的线程数。官方规定此值必须大于 0,也必须大于等于 corePoolSize,此值只有在任务比较多,且不能存放在任务队列时,才会用到;
- 第 3 个参数:keepAliveTime 表示线程的存活时间,当线程池空闲时并且超过了此时间,多余的线程就会销毁,直到线程池中的线程数量销毁的等于 corePoolSize 为止,如果 maximumPoolSize 等于 corePoolSize,那么线程池在空闲的时候也不会销毁任何线程;
- 第 4 个参数:unit 表示存活时间的单位,它是配合 keepAliveTime 参数共同使用的;
- 第 5 个参数:workQueue 表示线程池执行的任务队列,当线程池的所有线程都在处理任务时,如果来了新任务就会缓存到此任务队列中排队等待执行;
- 第 6 个参数:threadFactory 表示线程的创建工厂,此参数一般用的比较少,我们通常在创建线程池时不指定此参数,它会使用默认的线程创建工厂的方法来创建线程;
- 第 7 个参数:RejectedExecutionHandler 表示指定线程池的拒绝策略,当线程池的任务已经在缓存队列 workQueue 中存储满了之后,并且不能创建新的线程来执行此任务时,就会用到此拒绝策略,它属于一种限流保护的机制。
更多内容请参考:https://juejin.cn/post/7072921565079273480
10.拒绝策略有哪些?
线程池的拒绝策略默认有以下 4 种:
- AbortPolicy:中止策略,线程池会抛出异常并中止执行此任务;
- CallerRunsPolicy:把任务交给添加此任务的(main)线程来执行;
- DiscardPolicy:忽略此任务,忽略最新的一个任务;
- DiscardOldestPolicy:忽略最早的任务,最先加入队列的任务。
默认的拒绝策略为 AbortPolicy 中止策略。当然除了 JDK 内置的 4 种拒绝策略之外,用户还可以自定义拒绝策略,通过实现 new RejectedExecutionHandler,并重写 rejectedExecution 方法来实现自定义拒绝策略,实现代码如下:
public static void main(String[] args) {
// 任务的具体方法
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("当前任务被执行,执行时间:" + new Date() +
" 执行线程:" + Thread.currentThread().getName());
try {
// 等待 1s
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 创建线程,线程的任务队列的长度为 1
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, 1,
100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 执行自定义拒绝策略的相关操作
System.out.println("我是自定义拒绝策略~");
}
});
// 添加并执行 4 个任务
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
threadPool.execute(runnable);
}
11.你常用的拒绝策略是哪种?为什么?
最常用的拒绝策略是自定义拒绝策略,因为里面可以实现自己的业务代码,比如,我们可以通过自定义拒绝策略,发送警告信息给相关人员,这样就能及时发现程序执行的问题,同时再将拒绝的任务记录下来,让开发人员手动处理,这样就可以及时发现问题,并解决问题了。
12.三个线程交替打印ABC
三个线程交替打印 ABC 的实现方法有很多,我个人比较倾向于使用 JUC 下的 CyclicBarrier(循环栅栏,也叫循环屏障)来实现,因为循环栅栏天生就是用来实现一轮一轮多线程任务的,它的实现代码如下:
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
/**
* 3 个线程交替打印 ABC
*/
public class ThreadLoopPrint {
// 共享计数器
private static int sharedCounter = 0;
public static void main(String[] args) {
// 打印的内容
String printString = "ABC";
// 定义循环栅栏
CyclicBarrier cyclicBarrier = new CyclicBarrier(3, () -> {
});
// 执行任务
Runnable runnable = new Runnable() {
@Override
public void run() {
for (int i = 0; i < printString.length(); i++) {
synchronized (this) {
sharedCounter = sharedCounter > 2 ? 0 : sharedCounter; // 循环打印
System.out.println(printString.toCharArray()[sharedCounter++]);
}
try {
// 等待 3 个线程都打印一遍之后,继续走下一轮的打印
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}
}
};
// 开启多个线程
new Thread(runnable).start();
new Thread(runnable).start();
new Thread(runnable).start();
}
}
以上程序执行的结果如下图所示:
更多内容请参考:https://www.javacn.site/interview/code/weilai_thread.html
13.力扣括号生成
参考官方解题思路和实现代码:https://leetcode.cn/problems/generate-parentheses/solution/gua-hao-sheng-cheng-by-leetcode-solution/
参考&鸣谢
我没有三颗心脏
特殊说明
以上内容来自我的《Java 面试突击训练营》,这门课程是有着十几年工作经验(前 360 开发工程师),10 年面试官经验的我,花费 4 年时间打磨完成的一门视频面试课。学完训练营的课程之后,基本可以应对目前市面上绝大部分公司的面试了,并且课程配备了 9 大就业服务,帮助上千人找到 Java 工作,其中上百人拿到大厂 Offer,学员最高薪资 70W 年薪,面试课目录和 9 大服务如下:

加我微信咨询:vipStone【备注:训练营】
