Kafka 以其高吞吐量、低延迟和可扩展性而备受青睐。无论是在实时数据分析、日志收集还是事件驱动架构中,Kafka 都扮演着关键角色。
但是,如果 Kafka 使用不当,也可能会面临性能瓶颈,影响系统的整体效率。所以,了解如何提升 Kafka 的运行效率?对于生产环境的使用和面试都是至关重要的。
那么,提升 Kafka 性能的有效手段都有哪些呢?接下来,我们一起来看。
性能调优主要手段
Kafka 性能调优的主要手段有以下几个:
- 分区扩展
- 消息批发送(重要)
- 消息批获取(重要)
- 配置调优
- JVM 调优
1.分区扩展
在 Kafka 架构中,使用多分区(Partition)来实现数据分片功能。也就是 Kafka 会将多条消息并发存储到一个主题(Topic)的多个 Broker(Kafka 服务)中的多个 Partition 中,以实现并行操作的功能,极大地提高了整体系统的读写能力,如下图所示:
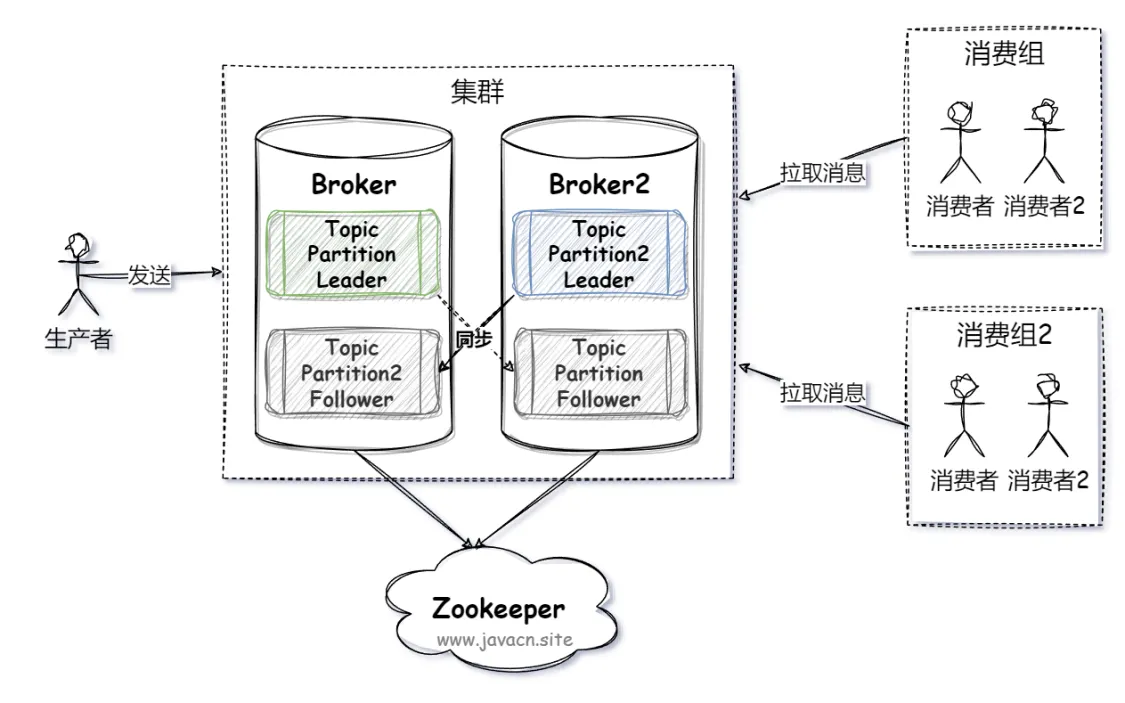
数据分片是一种技术将大数据分割成更小、更易于管理的片段(称为“分片”),并将分片都存储在不同的服务器上,从而实现了数据的水平拆分。通过数据分片,可以有效地解决单一数据库的性能瓶颈、存储限制以及高可用性等问题。
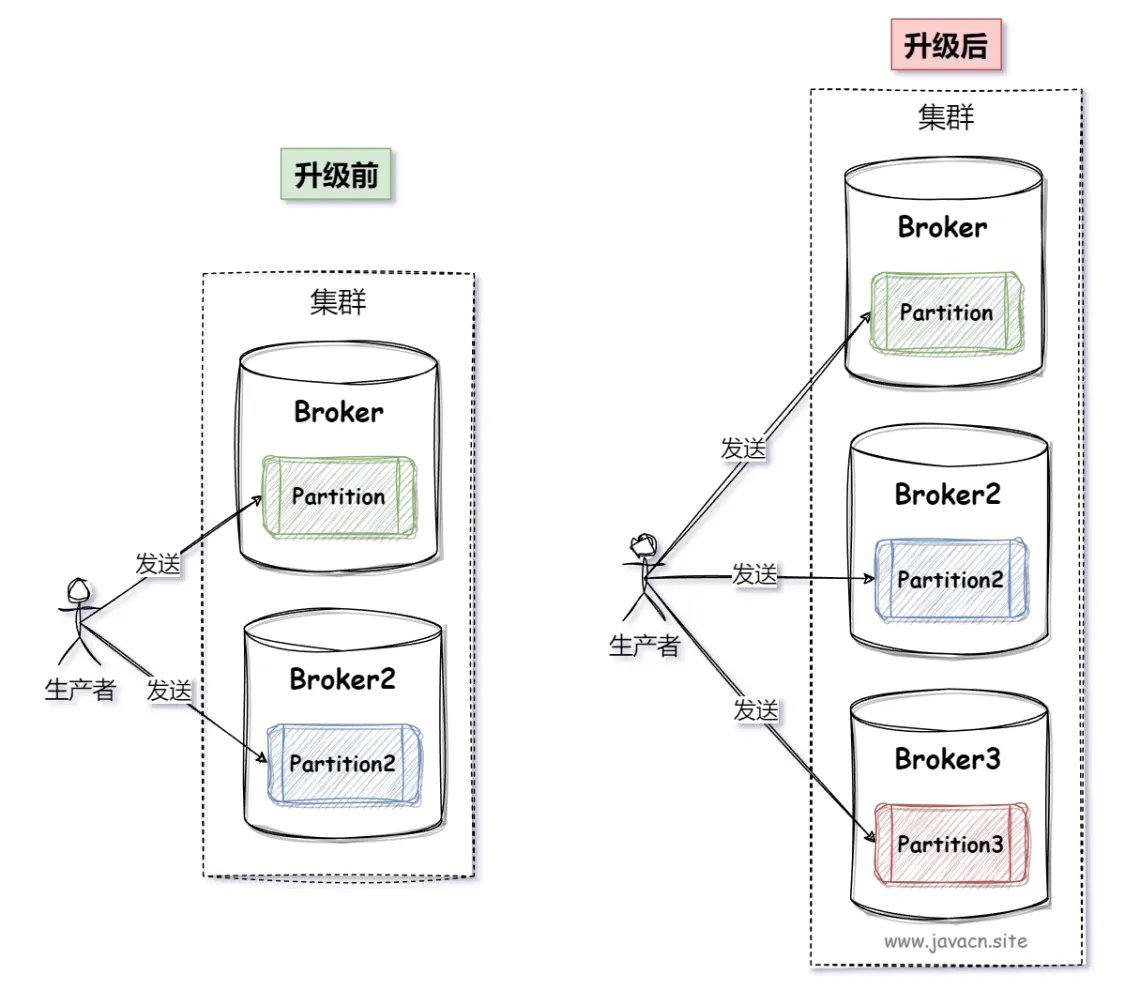
因此,增加更多的 Broker,扩展更多的分区 Partition 是提升 Kafka 性能的关键,如下图所示:
2.消息批发送(重要)
Kafka 默认是不支持批量发送消息的,然而开启批量发送消息可以提升 Kafka 整体运行效率。
为什么要批量发送消息?
批量发送消息有以下优点:
- 减少网络开销:当生产者发送消息给 Kafka 时,如果每次只发送一条消息,那么就需要建立一次 TCP 连接,这涉及到三次握手的过程。而如果采用批量发送的方式,则可以在一次 TCP 连接中发送多条消息,减少了网络连接建立和断开的次数,从而降低了网络开销。
- 减少 I/O 操作:批量发送意味着一次写入操作可以处理更多的数据。这对于磁盘 I/O 来说是一个优势,因为一次大的写操作比多次小的写操作更高效。
- 提高吞吐量:由于减少了通信次数,批量发送可以提高单位时间内发送的消息数量,即提高了吞吐量。
那么,想要实现 Kafka 批量消息发送只需要正确配置以下 3 个参数即可:
- batch-size:定义了 Kafka 生产者尝试批量发送的消息的最大大小(以字节为单位),生产者收集到足够多的消息达到这个大小时,它会尝试发送这些消息给 Kafka Broker,默认值为 16KB。
- buffer-memory:指定了 Kafka 生产者可以用来缓冲待发送消息的总内存空间,如果生产者试图发送的消息超过了这个限制,生产者将会阻塞,直到有足够空间可用或者消息被发送出去,默认值为 32MB。
- linger.ms:生产者在尝试发送消息前等待的最长时间(以毫秒为单位)。默认情况下,linger.ms 的值为 0,这意味着立即发送。
以上 3 个参数满足任一个都会立即(批量)发送。
因此我们如果需要匹配发送,主要需要调整的参数是 linger.ms,如下配置所示:
spring:
kafka:
bootstrap-servers: localhost:9092 # Kafka服务器地址
consumer:
group-id: my-group # 消费者组ID
auto-offset-reset: earliest # 自动重置偏移量到最早的可用消息
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 键的反序列化器
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 值的反序列化器
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 键的序列化器
value-serializer: org.apache.kafka.common.serialization.StringSerializer # 值的序列化器
batch-size: 16384
buffer-memory: 33554432
properties:
linger:
ms: 2000
3.消息批获取(重要)
Kafka 默认每次拉取一条消息,而使用批量获取消息可以有效提升 Kafka 运行效率。
为什么要批量获取消息?
批量获取消息有以下优点:
- 降低客户端处理开销:对于客户端来说,每次处理一个消息需要进行一系列的操作,如解包、解析、处理逻辑等。如果每次只拉取一个消息,客户端会频繁地进行这些操作,带来较大的处理开销。而批量拉取消息时,客户端可以一次性处理多个消息,减少了处理单个消息的频率,从而降低了客户端的处理开销。
- 减少网络往返次数:每次拉取一个消息时,客户端需要与 Kafka 服务器进行多次网络往返,包括发送请求、接收响应等。这些网络往返会带来一定的延迟。而批量拉取消息时,客户端可以一次性拉取多个消息,减少了网络往返的次数,从而降低了网络延迟。
- 优化内存使用:批量拉取消息可以更好地规划和利用内存。客户端可以一次性分配足够的内存来存储批量拉取的消息,避免了频繁地分配和释放小内存块的操作。这样可以提高内存的使用效率,减少内存碎片的产生,进而提升系统的运行效率。
- 提高吞吐量:批量拉取消息可以提高单位时间内处理的消息数量,从而提升了 Kafka 的吞吐量。
想要实现批量读取数据需要做以下两步调整:
- 在配置文件中设置批读取:
spring.kafka.listener.type=batch
- 消费者使用 List ConsumerRecord 接收消息,具体实现代码如下:
@KafkaListener(topics = TOPIC)
public void listen(List<ConsumerRecord<?, ?>> consumerRecords) {
for (int i = 0; i < consumerRecords.size(); i++) {
System.out.println("监听到消息:" + consumerRecords.get(i).value());
}
System.out.println("------------end------------");
}
以上程序的执行结果如下:
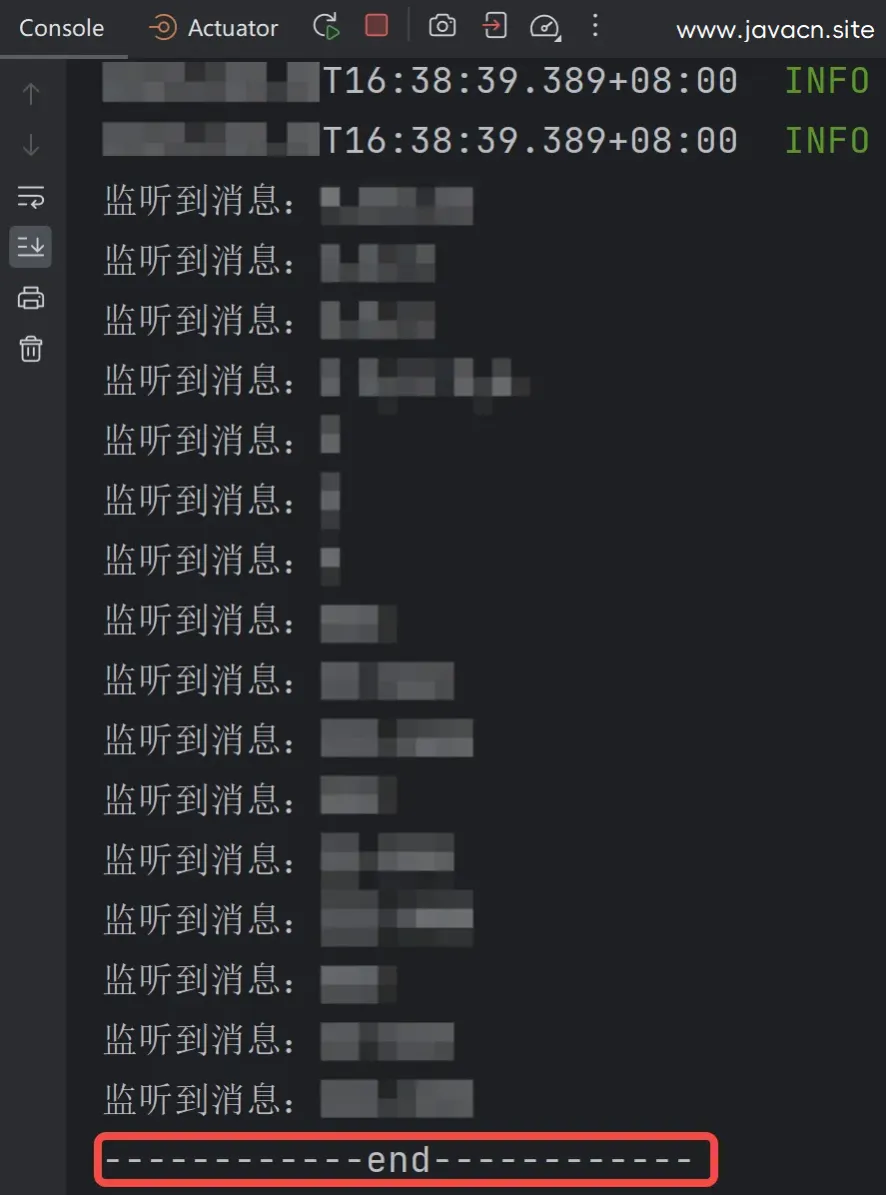
从执行结果可以看出:只有一个“end”打印,这说明 Kafka 一次拉取了一批数据,而不是一个数据,否则就会有多个“end”。
4.配置调优
合理设置 Kafka 的配置也可以一定程度的提升 Kafka 的效率,例如以下这些配置:
- 配置文件刷盘策略:调整 flush.ms 和 flush.messages 参数,控制数据何时写入磁盘。较小的值可以降低延迟,而较大的值可以提高吞吐量。
- 网络和 IO 操作线程配置优化:num.network.threads 应该设置为 CPU 核心数加 1,以充分利用硬件资源。调整 socket.send.buffer.bytes 和 socket.receive.buffer.bytes 以优化网络缓冲区大小,缓冲区越大,吞吐量也越高。
5.JVM 调优
因为 Kafka 是用 Java 和 Scala 两种语言编写的,而 Java 和 Scala 都是运行在 JVM 上的,因此保证 JVM 的高效运行,设置合理的垃圾回收器,也能间接的保证 Kafka 的运行效率。例如,对于大内存机器,可以使用 G1 垃圾收集器来减少 GC 暂停时间,并为操作系统留出足够的内存用于页面缓存。
课后思考
除了以上手段之后,我们还可以使用消息压缩等手段提升 Kafka 的运行效率。那么问题来了,如何开启 Kafka 的消息压缩?如何设置消息的压缩级别?
特殊说明
以上内容来自我的《Java 面试突击训练营》,这门课程是有着十几年工作经验(前 360 开发工程师),10 年面试官经验的我,花费 4 年时间打磨完成的一门视频面试课。学完训练营的课程之后,基本可以应对目前市面上绝大部分公司的面试了,并且课程配备了 9 大就业服务,帮助上千人找到 Java 工作,其中上百人拿到大厂 Offer,学员最高薪资 70W 年薪,面试课目录和 9 大服务如下:

加我微信咨询:vipStone【备注:训练营】
